

Getting to the next level with your data
Looking towards the future and finding the best route to the top


Thanks to everyone who gave me a ton of great feedback on my article about Data Lakes and Ecosystems. It's still getting a lot of hits and 'likes', and readers wanted to know what comes next. I had a great conversation this week about different forms of analytics data models and what a potential strategy could look like for making insights available based on an employee's persona. Here's my take on how you can merge these topics together to produce something real in your company.
As mentioned in the previous article, there is no "one-database/warehouse/lake to rule them all" (ref 'Lord of the Rings' by J.R.R. Tolkien). Data & Analytics leaders need to think about the ecosystem of data structures and tools that will make up their enterprise environment. Part of that decision-making should take employee personas into mind. The data lake, for example, will be built primarily for data scientists by ingesting many source systems from all parts of the company into one central place. The bedrock of the lake should be the actual source system tables, unaltered, in something of a massive hall of mirrors. Data scientists will be itching to get access so they can start building algorithms that find relationships in the otherwise disconnected data. They can also use this data as training data for all kinds of machine learning algorithms, because these tables represent what algorithms will actually see “out in the wild”.
HERE BE DRAGONS!
But for some other personas, there should be a big, virtual sign reading, “HERE BE DRAGONS!” to heed caution to them about it. The lake is a treacherous place for the uninformed user to start coding in/analyzing data. Many analysts and business leaders will need the data to be sanitized and harmonized before it represents reality for them. This is where the use-case for a data warehouse came from in the past, and from where the use-case for “certified data models” now comes.
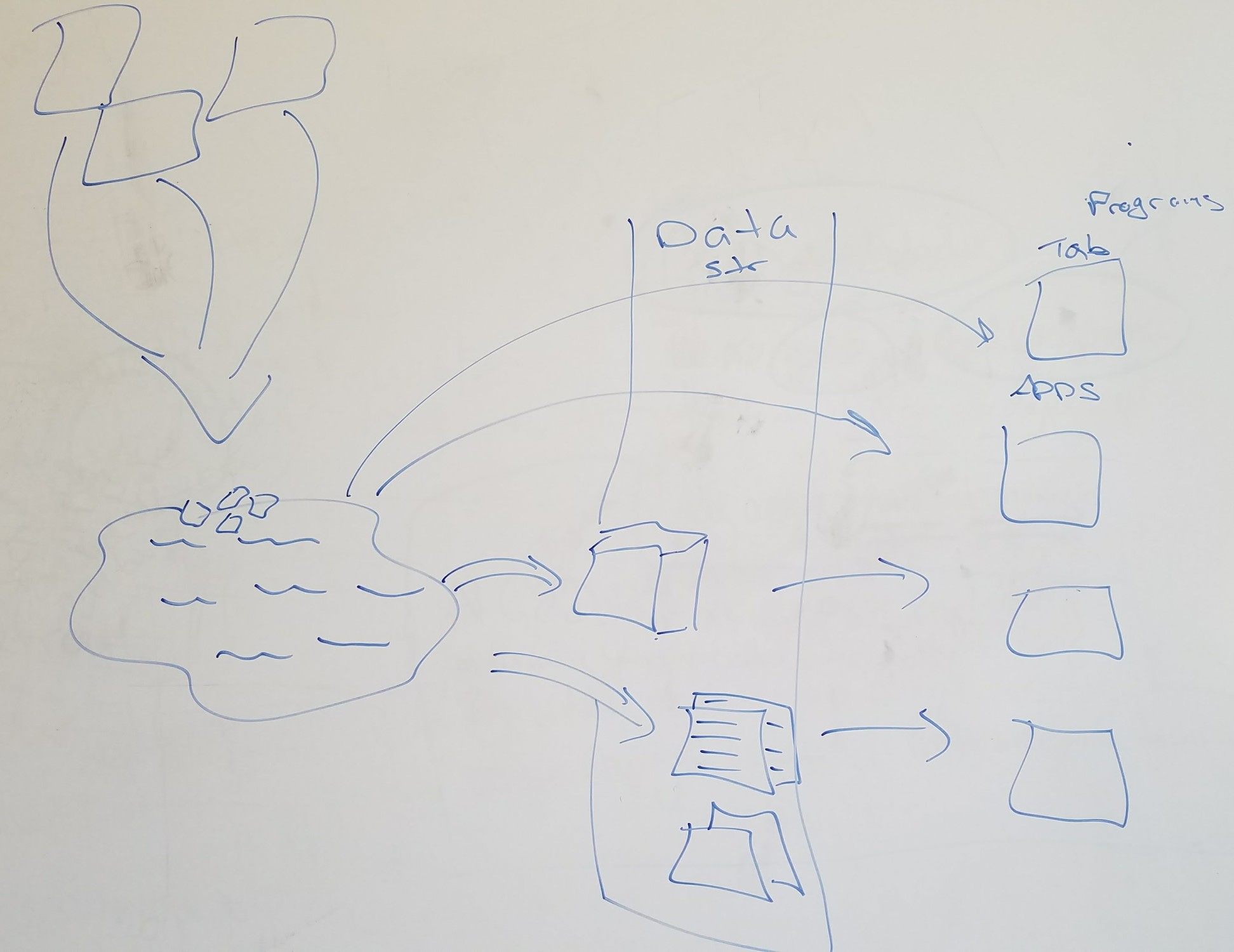
Certified data models weave together related data from various source systems into one, consistent view of the world. Think of a company that has many divisions. Some of the divisions may be using Oracle-based applications while others are using SAP. Oracle and SAP have very different ways of describing things like Purchase Orders (for example), but for financial analysts to prepare a view of the company, they need to manually harmonize the data from these behemoth systems. A systematic way to perform those operations, taking all of the source system data from the lake, would save analysts a ton of manual calculation time while providing a consistent view of the company’s financial health every time. Moreover, building these connectors by technology (e.g. Oracle, SAP) means that you can then plug in N-number of additional data sources that use those technologies with very little rework...plug-and-play never felt so sweet.
The technology that you use to build the actual data models will depend on the outcomes you wish to drive. You may need an Essbase cube to allow quick, multi-dimensional drill down into various, pre-built business calculations. You may need a flat, JSON file fed into Lucene to allow for sub-zero search operations with ElasticSearch. There may be many production-ready data models built from the basis of the lake, each tailored to deliver persona-based outcomes depending on who your business users are and what insights they need at their fingertips.
Have you started to think of the data lake as a starting point for your algorithm-driven enterprise? Have you also thought about other ways to take the data and mash it into insight-based applications for business users? Share a comment below to keep the conversation going. Follow me, and ‘like’/share this article to spread the word on how to take data to the next level.
Matt Brooks is a seasoned thought leader and practitioner in data and analytics; culture; product development; and transformation.