

You can't have scalable AI Ready Data w/o taking Step 1
Enterprises need to re-focus on building a Trusted Data Environment, something that was historically deprioritized and now has the ultimate business case

📌 The point is: All data can be used for AI… if it can be trusted.
The term “AI-ready data” has been used a lot lately with no real definition as to what it actually entails. This has led practitioners to wonder if data offices will be able to check a box one day saying that an enterprise’s data is “AI Ready”.
The truth? You don’t make data ready for AI—you make your systems ready to handle data in a way that earns trust. In that way, you take the first step in preparing your data to be curated and turned into reusable data assets and features that analytics professionals, data scientists, and business leaders feel comfortable feeding into AI models.
This also builds trust in the outputs of AI models
Check out the whitepaper (paywall) for much more details around the business case, structure, and importance of building your data infrastructure!

For years, CDAOs and Chief Architects pitched business cases for foundational data work—pipelines, master data, catalogs—only to hear, “What’s the ROI on clean data?” And honestly? The returns were there… but they were buried in avoided rework and long-term agility. In a day and age where Chiefs could task junior employees to do manual reports, including incredible amounts of manual manipulation to get numbers to “look right”, from their perspective the juice just wasn’t worth the squeeze.
Now with Agentic AI knocking at our doors, the need isn’t abstract anymore.
“AI has put a mirror in front of companies, showing them the work they have to do to leverage their data.”
— Fortune 500 CDO, via CIO.com
That work starts with building an environment where all data is discoverable, trusted, and usable—with accountability built in. Here’s how to do it.
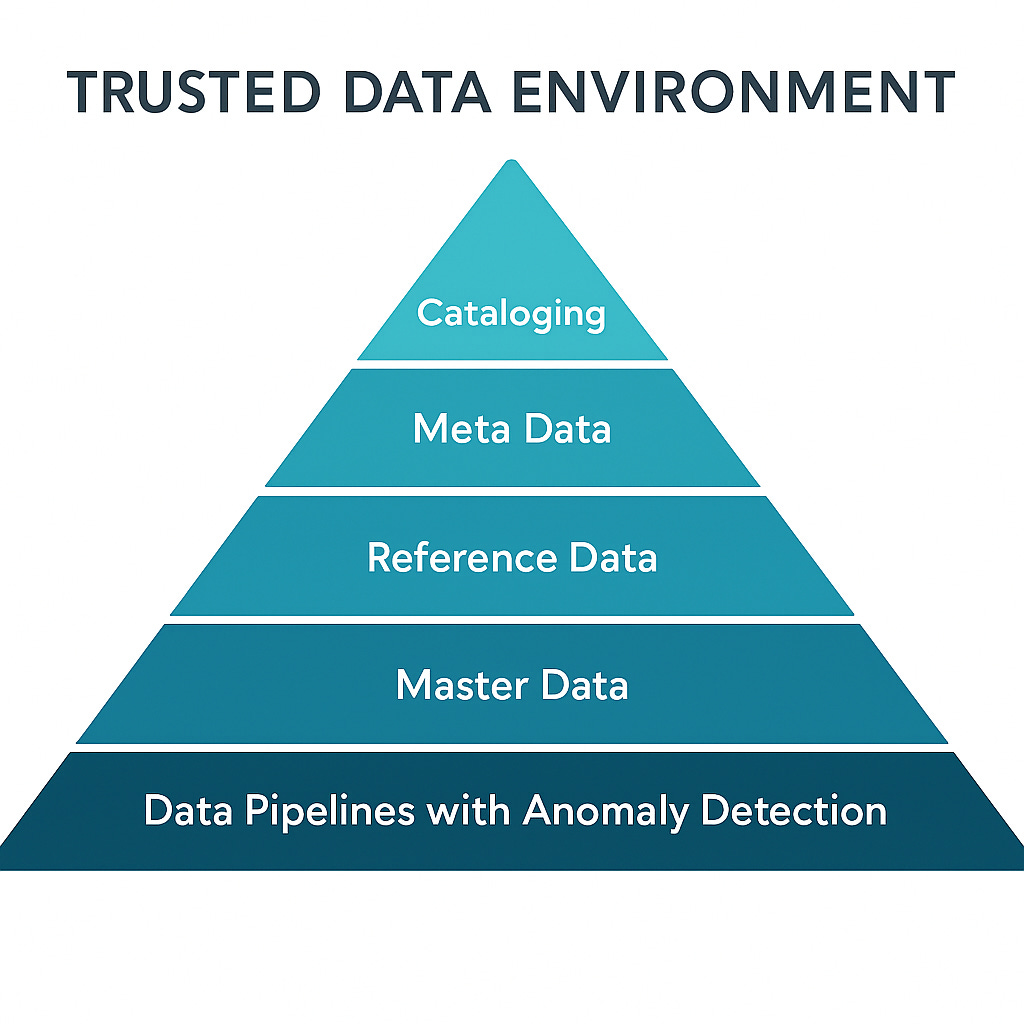
🔻 Data Pipelines with Anomaly Detection
You don’t get AI reliability from batch jobs and blind trust. You get it from observability.
Your data pipelines need built-in anomaly detection that alerts you when something unexpected happens—like volume spikes, schema drift, or a sudden drop in values. Think of it like site reliability engineering, but for data.
A global bank recently implemented ML-powered monitoring across their daily risk reporting pipelines. When a source system failed to deliver its batch, the observability layer flagged the missing data before it corrupted downstream models. That’s not just a tech win—it’s regulatory risk avoided. Similarly, even when a batch finishes “successfully”, post-job analytics to determine if volumes are as expected for any given day of the week could make a huge difference before undetected errors creep into dashboards and models for weeks before anyone notices.
This kind of proactive, intelligent monitoring is the difference between building on rock versus sand.
🔻 Master Data
You want AI to make decisions on behalf of your business? Then it better know who your customers, products, and suppliers actually are.
Master Data Management (MDM) unifies core entities across systems. In insurance, we’ve seen MDM unify customer records across policy, claims, and call center systems—so models can predict churn or upsell accurately.
Without MDM, your AI thinks “John A. Smith,” “J. Smith,” and “Smith, Jonathan” are three different people. That’s how you train a model to fail.
Don’t just stop at customer data. Your master data should include all critical data used to drive your business such as your list of products and their statuses, your key suppliers and partners, and other critical lists of business entities.
Supply chain MDM prevents duplicate payments. Healthcare MDM ensures you’re linking the right patient to the right outcomes. It’s not sexy—but it’s critical infrastructure for everything AI touches.
🔻 Reference Data
If master data defines the nouns, reference data governs the vocabulary—statuses, categories, types, codes.
It’s often overlooked. But it shouldn’t be.
Financial firms deal with a mess of reference data: ISINs, CUSIPs, internal codes, mappings. One trading desk might call a bond “CMBS” while another logs it as “CommMtgBond.” AI models trained on both will get it wrong unless reference data is standardized and centrally managed.
In healthcare, standardized procedure codes like ICD-10 or SNOMED CT are how AI safely interprets patient data. Misaligned codes can mean the difference between a correct diagnosis and a liability.
Reference Data Management (RDM) is the glue that binds your datasets into something meaningful. If you’re not governing it, you’re inviting misinterpretation at scale.
🔻 Metadata
This is where AI governance really starts.
Metadata tells us where the data came from, how it was transformed, how fresh it is, and who owns it. Without it, there’s no explainability, no audit trail, and no accountability.
If you’re a bank governed under BCBS 239, lineage tracking is already a requirement. But it’s also just smart practice. You want your models to be transparent? Start by making your data transparent.
In one real-world example, a healthcare org used metadata to flag that a chunk of diagnostic device data came from an instrument with a known calibration issue. They pulled it from the training set—preventing the AI from learning garbage.
Metadata is not a documentation exercise. It’s the control system for your AI ecosystem. It can be passive, like a thermometer, giving general information about data assets. It can also be active, like a thermostat, triggering events automatically within your ecosystem when certain conditions are met.
This is how Agents will be invoked and help automate your business in the not-too-distant future!
🔻 Cataloging
Here’s the final layer—and the one that puts everything else to work.
A good data catalog is more than a list. It’s a trust layer. It’s where teams go to discover curated, certified, governed data products they can use confidently for AI training, dashboarding, or analysis.
Done well, a catalog connects business users to “golden datasets” and connects models to the latest, validated sources. Done poorly, it becomes a digital junk drawer.
In insurance, a well-built catalog helps underwriters or product teams find existing data features for pricing models—without reinventing them. In financial services, it keeps regulators happy by providing lineage, definitions, and ownership on demand.
Your catalog is your front door to AI enablement. Lock it, label it, and make it safe. It’s probably the most critical element to get right, ensuring your employees don’t go around your trusted data environment to recalculate key business indicators or source raw, uncurated data from systems directly.
Final Word
Building AI-ready infrastructure isn’t a back-office exercise anymore. It’s strategic. It’s visible. And it’s absolutely required if you want to move fast, stay compliant, and scale intelligently.
“AI cannot exist without data, and it all begins with a strong data foundation.”
— CDO, Global Pharma
You don’t need perfect data. You need infrastructure that makes imperfect data usable and trustworthy.
That’s what earns your org the right to build models, launch agents, and ship products powered by AI.
Matt Brooks is a seasoned thought leader and practitioner in data and analytics; culture; product development; and transformation.